vidéo - slides (voir aussi la page d'origine sur fdn.fr)
Transcription
(basée sur la transcription de l'April)
Organisateur : Bonsoir à tous. Bienvenue à Sciences Po et merci d’être venus en amphi Boutmy pour la première partie du cycle organisé par Libertés numériques sur le thème « Qu’est ce que l’Internet ? ». Libertés numériques, c’est l’association des étudiants de Sciences-Po, qui donc a souhaité organiser en partenariat avec le médialab de Sciences-Po, cette conférence et donc je vais tout de suite céder la parole à Dominique Boullier pour qu’il nous présente ce qu’est le médialab et quelles sont ses activités.
Dominique Boullier : Je suis Dominique Boullier. Je suis professeur de sociologie ici à Sciences-Po et je suis coordinateur scientifique du médialab avec Bruno Latour, par ailleurs chargé de mission auprès du directeur sur les stratégies numériques. Le médialab, lui est un outil à destination des chercheurs, donc les étudiants n’en ont pas souvent entendu parler peut-être, mais l’objectif, c’est bien de faire en sorte que les chercheurs comprennent non seulement qu’ils ont à leur disposition des outils absolument puissants et inédits en matière de recherche mais qu’ils ont aussi, la matière première. On est sur des réseaux qui génèrent, où nous générons, les uns et les autres, beaucoup de traces avec les problèmes que ça pose, vous le savez bien, mais qui sont aussi une merveille pour les chercheurs en sciences sociales ; et donc on a de quoi, moissonner énormément de données, apprendre à les structurer, à les traiter sur le plan linguistique notamment à travers tout ce qu’on peut ramasser et à les présenter à travers des cartographies diverses et variées pour essayer de manipuler ce que nous appelons des datascapes. Donc tout ce travail là, c’est quelque chose qui est une façon de changer la façon de faire de la recherche, qui est très importante à Sciences-Po, sur tous les sujets qui intéressent les chercheurs. Bien évidemment, Internet n’est pas seulement une affaire de chercheurs, même pas une affaire seulement d’ingénieurs, ce n’est pas une affaire de geeks, ça concerne tous les citoyens. Et c’est cela qui nous importe aussi. Dans le cours que je donne sur les enjeux socio-politiques du numérique, mon seul objectif, c’est vraiment d’arriver à faire en sorte que tous les étudiants de Sciences-Po, enfin tous ceux au moins que je vois, comprennent à quel point la politique qu’ils peuvent mener ou les grands discours et débats génériques que l’on a, ne valent pas grand chose tant qu’on est pas capable de rentrer dans le code, tant qu’on est pas capable de s’intéresser sérieusement à ce qui se fait, parce que c’est là où se fait la politique actuelle, la politique de demain aussi. Et qu’il y a à chaque fois, à chaque décision technique : il y a des choix politiques qui sont faits. Et donc, si nous ne sommes pas capables d’avoir un minimum de culture technique dans ce domaine eh bien nous abandonnons des grands leviers d’organisation de notre société. Nous l’abandonnons à quelques uns et à partir de ce moment là, il ne faudra pas se plaindre de se trouver dans des structures que nous n’avons pas forcément voulues. Donc, tout le travail, comme on dit effectivement « Si vous ne vous occupez pas du code, le code lui s’occupe de vous », comme on dit à propos de la politique. Eh bien c’est vrai ! Il faut mettre le nez dedans et alors à cette occasion là, j’ai l’occasion de faire voir des vidéos de Benjamin Bayart, parce que non seulement on met le nez dans le code mais en plus on ne s’ennuie pas, puisque vous le savez c’est toujours très stimulant de l’écouter. Je pense qu’il y a là une grande chance pour nous à Sciences-Po, d’avoir Benjamin Bayart et j’espère que vous serez assidus à ses conférences, pour la suite des opérations.
Et merci à Libertés numériques, qui est une preuve que les enjeux du numérique ont été pris en compte maintenant par les étudiants eux-mêmes et directement.
Organisateur : Justement, en vraiment quelques mots : Libertés numériques, c’est une association qui a été crée il y a deux ans pour promouvoir le logiciel libre et l’éthique qu’il véhicule, donc le partage de la connaissance pour une société qui respecte nos libertés numériques, nos libertés individuelles ; et nos buts sont de développer l’esprit critique en la matière, de la part des étudiants de Sciences-Po, donc de promouvoir la connaissance et le débat sur les problématiques du numérique et donc également d’organiser des conférences comme celles-ci.
Ce cycle est en trois parties, la première partie ce soir. La seconde partie le 19 avril à 19h15, en amphithéâtre Jean Moulin, qui est juste à côté et enfin la troisième partie, le 4 mai à 19h15 à l’amphithéâtre Caquot qui est dans l’ancienne École Nationale des Ponts et Chaussées. Sans plus tarder, je cède la parole à Benjamin Bayart, pour la première partie.
Benjamin Bayart : Merci. Je suis toujours épaté quand j’arrive à voir Linux projeter quelque chose sur un écran. J’ai quand même fait quelque chose de pas très sympa avec les pauvres gens qui ont organisé ça, c’est que j’ai décidé de ce que je mettrai exactement dans les trois volets : de mémoire ça doit être lundi soir, tard, donc forcément ça n’a pas pu être pour le moment sur les affiches.

Donc, j’ai décidé de travailler sur ce cycle de trois conférences, en abordant d’abord dans la première partie le réseau de transport. Parce qu’on ne peut pas parler d’Internet sans parler de réseau. Si j’essaie de vous faire comprendre ce que c’est qu’Internet, il faut d’abord que je vous explique ce que c’est qu’un réseau, comment ça marche, qu’on essaie d’enlever le maximum de magie dedans. Donc, en fait, là-dedans, je ne vais pas parler de politique, je vais pas parler d’impact social, je ne vais pas parler de tout ce qu’Internet apporte ou n’apporte pas. Par contre, j’espère que vous en ressortirez, en ayant compris 75 % de ce que je raconte, en ayant retenu 5 % et que les 5 % en question fassent que vous compreniez que le réseau n’est pas magique, qu’il fonctionne de manière relativement simple, avec des techniques pas très compliquées à comprendre, et des enjeux politiques derrières qui sont, par contre, énormes.
La deuxième conférence sera consacrée aux applications. Là encore, j’essaierai de rester sur un exercice de vulgarisation scientifique. Mon but étant que vous compreniez ce qu’est une application sur Internet, comment ça marche, les différentes variétés d’applications, comment ça se réfléchit, comment ça s’utilise et que vous appreniez à avoir un point de vue beaucoup moins utilisateur et beaucoup plus d’architecte sur : qu’est ce que ça fait ? Qu’est ce que ça fait de bien ? Qu’est ce que ça fait de pas bien.
Et enfin, dans la troisième conférence, je vais vous parler des impacts politiques et sociétaux de tout ce merdier. Je sais très bien que pour venir parler à Sciences-Po, vous avez envie de le lire à l’envers. C’est-à-dire que le volet qui vous intéresse, c’est le troisième ; or le problème c’est que vous ne pouvez pas réfléchir à quoi que ce soit de sérieux sur le troisième si vous n’avez pas compris les deux premiers. Je pense que la majorité des gens de Sciences-Po qui seront amenés à voir ces conférences, verront d’abord la troisième et ensuite arriveront probablement à la conclusion qu’ils auraient mieux fait de regarder les deux premières.
C’est pour ça que j’espère que c’est enregistré, j’espère que ça marche.
En particulier parce que, si un jour vous êtes amenés à débattre des enjeux politiques d’Internet avec quelqu’un qui est plus compétent que vous techniquement, mettons par exemple que vous essayiez de soutenir une opinion qui ne soit pas la mienne dans une discussion avec moi : vous n’avez aucune chance. Même si vous avez raison, ce n’est pas le problème. Il me faudra à peu près trois minutes pour vous embobiner techniquement dans n’importe quoi et vous noyer. Si vous n’êtes pas capables de repérer à quel moment je vous mens, à quel moment j’essaie de vous enfumer, il n’y a pas de discussion possible. Exactement de la même manière que on ne peut pas débattre de la liberté de la presse et de la liberté d’expression qui va avec, si on ne sait pas lire, simplement parce qu’on ne comprend pas l’enjeu. De la même manière, aussi longtemps que vous serez des illettrés du numérique, vous n’avez aucune chance de pouvoir mener une discussion politique autour d’Internet et il se trouve que c’est un des enjeux politiques majeurs du XXI° siècle. Voilà pourquoi je voulais venir expliquer ça, ici.
Cette petite introduction étant faite, de quoi je vais vous parler ? En fait essentiellement de technique, le seul moment où je vais pas parler technique c’est quand on en sera à peu près là. Tout le reste, c’est de la technique, c’est pour que vous compreniez ce qui se passe quand vous tapez quelque chose dans votre navigateur.
Donc la première spécificité d’Internet, en tant que réseau, c’est qu’il est basé sur de la commutation de paquets et non pas sur de la commutation de circuits. Il y en a combien qui ont compris dans la salle ? On reconnaît bien le troupeau d’informaticiens ! Donc, je vais commencer par expliquer ce que c’est que de la commutation de circuits pour pouvoir à l’opposé expliquer ce que c’est que de la commutation de paquets. À partir de là, je parlerai un tout petit peu de routage. Ensuite, on verra ce que c’est qu’une application, ce que c’est qu’une adresse, ce que c’est qu’un port. Ensuite, on verra ce que c’est que de la traduction d’adresses. Normalement, quand on aura fini la traduction d’adresses, vous serez à peu près capables de comprendre ce qui se passe quand vous consultez un site Web depuis chez vous. Et puis j’essaierai en conclusion de synthétiser l’ensemble de manière à ce que vous repartiez avec les 5% à retenir, en espérant que vous ayez compris les trois quarts du reste au-dessus.
J’ai pas appliqué mes règles de trois habituelles mais je pense que j’en ai à peu près pour une heure. Bien, alors on va commencer par les choses intéressantes : la commutation de paquets.
Pour expliquer la commutation de paquets, il faut commencer par expliquer la commutation de circuits. La commutation de circuits, c’est la façon dont fonctionnaient tous les réseaux jusque dans les années 70. En particulier, c’est comme ça que fonctionne le réseau téléphonique. Le principe, c’est que pour relier deux points sur le réseau, on va créer un circuit continu allant du point A au point B. Exactement ce que vous constatez sur un réseau électrique chez vous. Quand vous allumez une ampoule, quand vous allumez une lampe, en bougeant un interrupteur, vous créez un circuit qui relie l’ampoule au réseau électrique et qui fait qu’il y a de la lumière. Quand vous basculez l’interrupteur dans l’autre sens, vous coupez le circuit : ça supprime la lumière.

Donc ça c’est à peu près ce qu’avait compris Graham Bell, quand il s’est intéressé au téléphone : on crée des circuits. Ça suppose en fait, de pré-réserver pendant le moment, après que vous ayez composé le numéro et avant que ça sonne, les bidibidibidip que vous entendez, c’est le réseau qui est en train de chercher à pré-réserver le circuit. Une fois que ça sonne à l’autre bout, le circuit est construit. Et pour faire ça le réseau a besoin de connaître complètement la topologie du réseau, c’est-à-dire de savoir entièrement de quoi il est constitué pour savoir par où passent les appels.
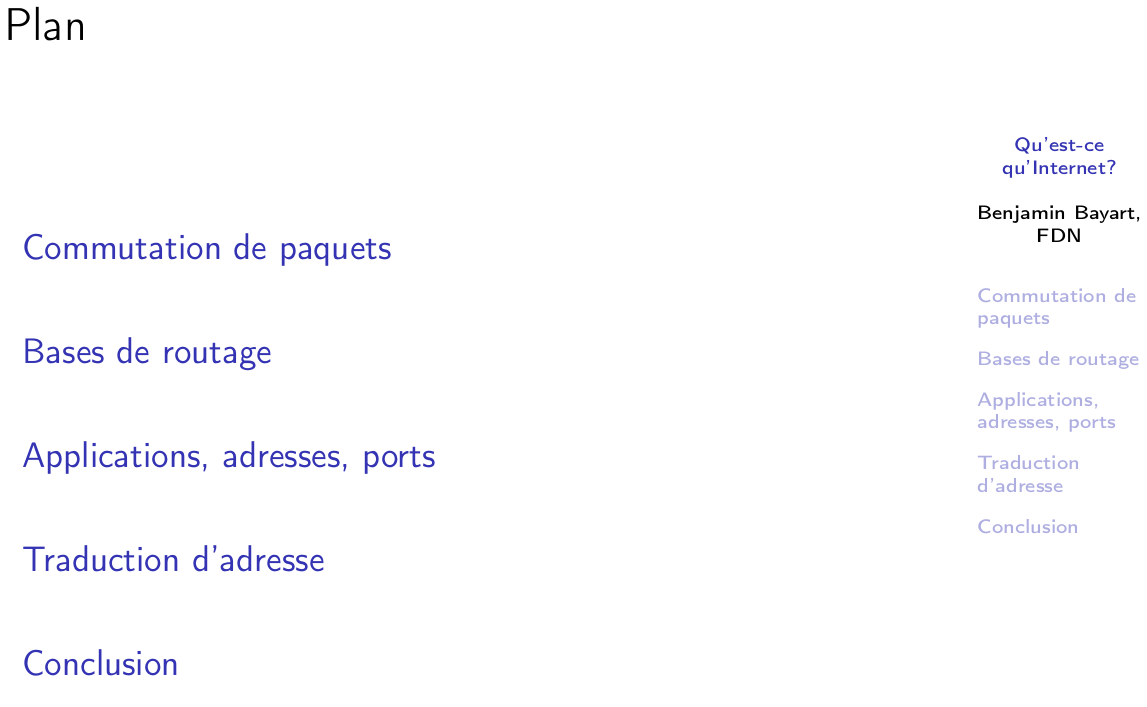
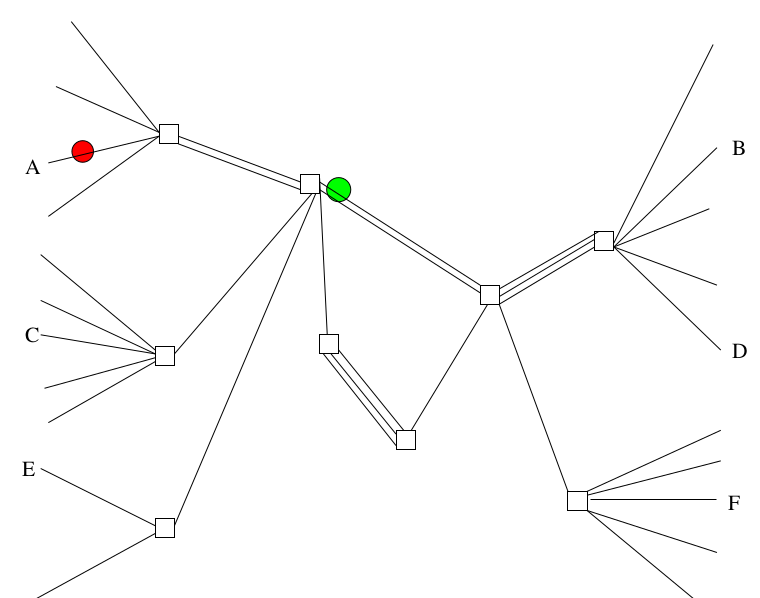
Alors pour ceux d’entre vous qui comme moi ont plutôt une mémoire visuelle, voilà ce que ça donne visuellement.
C’est un réseau. Chaque carré correspond à un nœud d’interconnexion, chaque trait correspond à, basiquement, une ligne possible dans le circuit. Alain, Bernard, Chantal, David, Édouard, Françoise, six personnes reliées au réseau.
Quand on établit une connexion, quand on fait échanger Alain et Bernard : on réserve tout un circuit sur l’intégralité du réseau. Même pendant les périodes où on ne dit rien au téléphone, le circuit est réservé.
Voilà une deuxième communication, jusque-là tout va bien. Pourquoi est-ce qu’on a besoin de connaître la topologie complète du réseau ? Simplement parce que pour créer la troisième communication entre Édouard et Françoise, il y a un problème, c’est que le chemin passe par un point de congestion. C’est-à-dire que, là, le réseau, quand il va calculer le circuit qu’il aurait voulu établir, il aimerait passer par le tronçon où il y a deux lignes rouges et bleues, sauf que ce tronçon là, il est saturé. Et donc, pour pouvoir trouver la voie de contournement et réserver le chemin complet, il y a besoin d’avoir une connaissance complète du réseau, pour simplement savoir créer ce détour.
Ça, c’est le principe d’une communication par circuits.
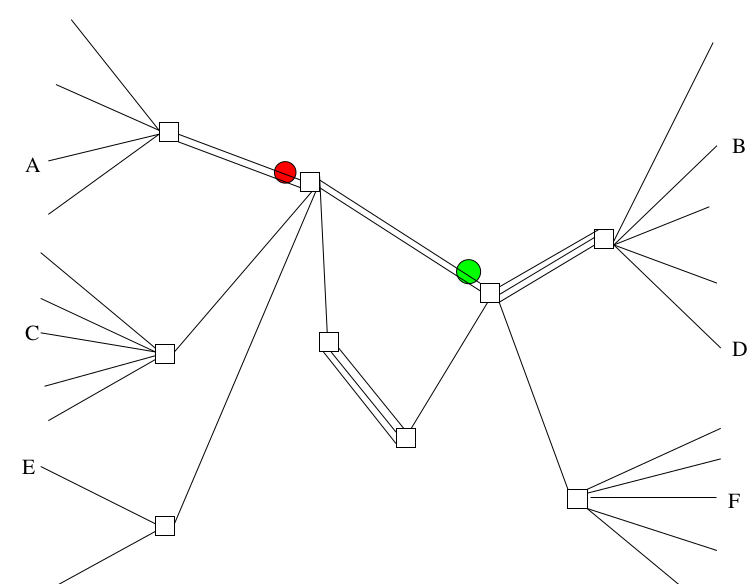
La commutation par paquets se fait de manière très différente : chacun envoie des paquets d’informations, donc pas un flux continu mais simplement un paquet d’informations. Si je garde le rapport avec le téléphone, c’est un poullième de seconde de discussion. Faut savoir qu’un paquet de données, c’est quelques millisecondes d’une discussion.

Chaque nœud du réseau va décider de ce qu’il fait du paquet en fonction de la connaissance qu’il a de son voisinage et non pas de la totalité du réseau. Et il va prendre sa décision, non pas pour toute une discussion, mais paquet par paquet. C’est-à-dire que dans le cas de congestion qu’on avait au-dessus : on ne va pas avoir une distribution très, très claire de deux conversations, rouges et bleues qui passent sur le tronçon principal et d’une conversation d’une communication verte, qui est déviée. On va avoir, en fait, les trois parfaitement mélangées sur le tronçon principal et le tronçon accessoire, ce qui est quelque chose de techniquement très différent.
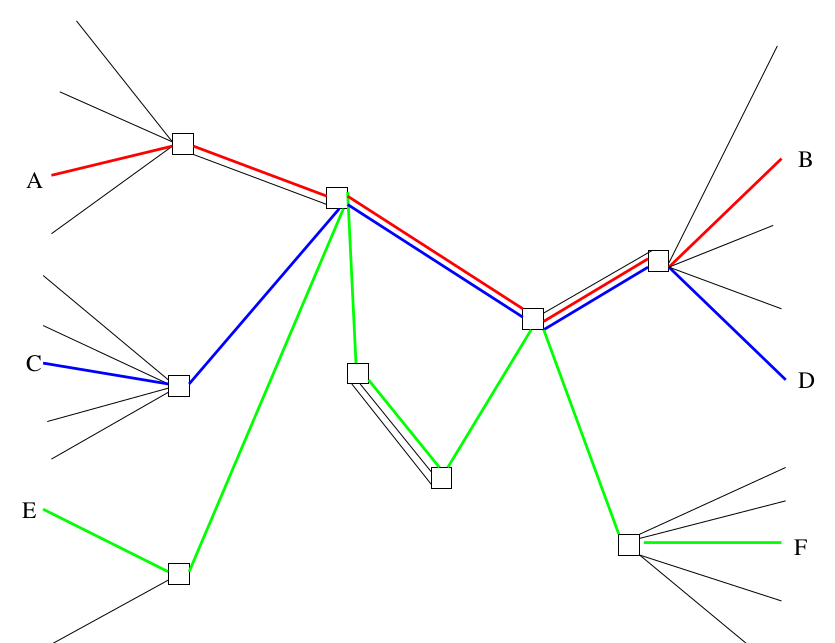
Alors, voilà une représentation schématique du même réseau sur lequel on ferait de la commutation de paquets et ça ressemble à quelque chose comme ça.
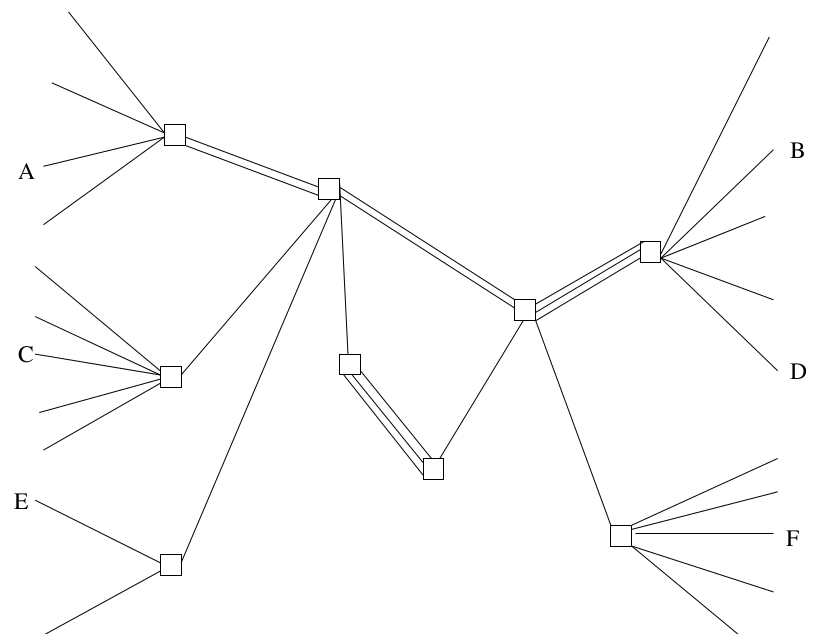
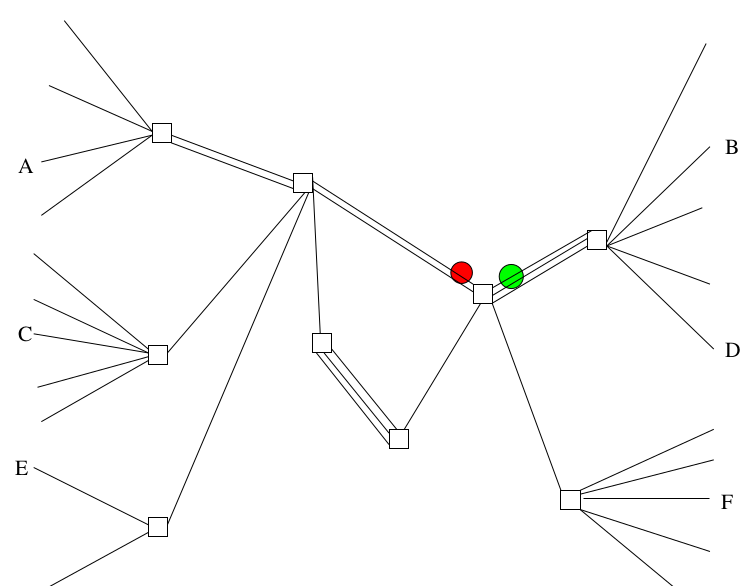
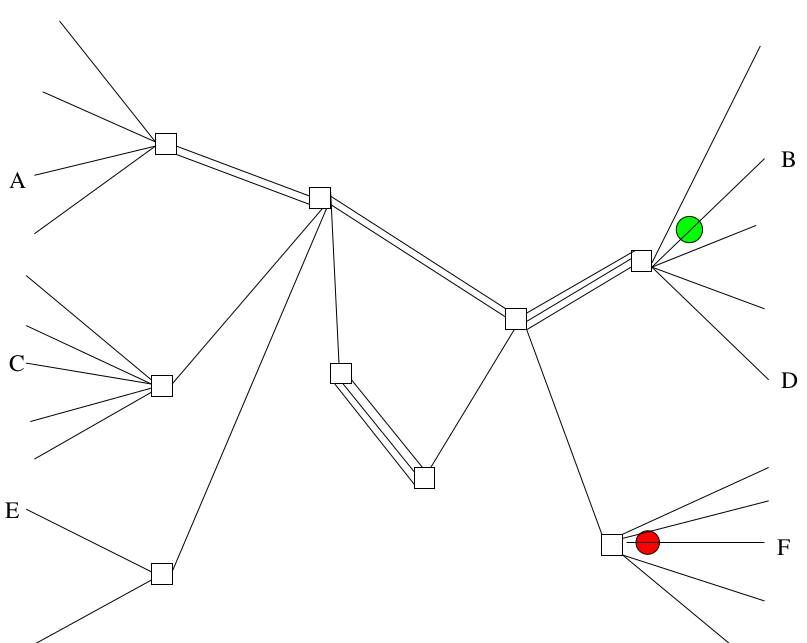
L’émission d’un paquet qui est transporté, l’émission d’un deuxième qui est transporté. La grande différence, c’est que mon interlocuteur A, qui tout à l’heure ne parlait que à B, là, a été capable, en parfait mélange, d’envoyer certaines données à destination de B, d’autres données à destination de F. Ça, c’est l’aspect très novateur des réseaux à commutation de paquets à la fin des années 70. Le même terminal, c’est-à-dire en fait, votre ordinateur chez vous, peut discuter avec plusieurs serveurs en même temps, en parallèle, sans que ça se mélange. Ce qui n’était pas possible sur les réseaux précédents. Il y en a à peu près aucun de la bonne génération, les gens qui ont connu le Minitel, ils savent : on peut consulter un service Minitel puis un autre, mais pas deux en même temps alors que vous savez tous, couramment, être sur deux sites Web en même temps.
Donc, ça, c’est le premier morceau important à comprendre, sur Internet, on raisonne paquet par paquet, jamais par circuit.
Question : Dans les années 70, qu’est ce qu’ils transportaient dans leurs paquets ?
Benjamin Bayart : Dans les années 70, qu’est ce qu’ils transportaient dans leurs paquets ? Internet.
Question : D’accord !
Benjamin Bayart : Ça a 40 ans, Internet, et donc les tout débuts d’Internet sont liés aux tout premiers essais de réseaux à commutation de paquets. Un des premiers réseaux à commutation de paquets qui n’a pas survécu c’est Cyclade, qui était une initiative française et qui est parfois considéré comme un des ancêtres d’Internet.
Donc, la commutation de paquets, ça vient de France. Internet, ça vient des États-Unis, ça prouve qu’ils avaient bien compris le concept.
Bien. Maintenant qu’on a compris qu’on transportait des paquets, on va essayer de comprendre comment chacun de ces paquets se transmet.
En particulier, je veux que ça soit très clair pour vous : quand on télécharge un fichier, à moins que le fichier soit ridiculement petit, il n’existe pas une connexion continue entre le serveur qui envoie le fichier et votre client qui le reçoit. Le serveur envoie des tous petits bouts de fichiers qui se perdent dans le réseau et reviennent à l’autre bout. Comme fort heureusement, les bouts ont été numérotés, en les remettant dans le bon ordre, on ré-obtient le fichier. Mais je veux bien que vous soyez conscients de ça.

Bien. Le routage le plus simple à comprendre, c’est du routage statique, c’est-à-dire qu’on dit à une machine : pour telle destination, tu enverras à tel intermédiaire ; et le cas le plus simple étant, quand on a une route par défaut - ce qui est le cas chez vous où je suppose que la majorité d’entre vous n’a qu’un seul fournisseur d’accès, en fait votre machine sait que la sortie c’est par là, puis ça suffit comme routage. C’est exactement comme du routage routier. Quand vous sortez de votre garage, basiquement, il n’y a qu’une seule allée pour sortir. Ça se complique sitôt que vous êtes au portail, il faut choisir s’il faut aller à droite ou à gauche ; mais juste sortir de chez vous en général, c’est une route par défaut.
Voilà comment ça se formule une route :

Moyennement lisible. Alors : 192.168.0.0/24 via 1.2.3.4, ça dit pour joindre telle plage d’adresses IP, faire suivre à telle personne. Si on traduit en sensiblement plus français : pour toutes les adresses qui sont comprises entre machin et truc, il faut faire passer par ça.
Pourquoi je vous emmerde avec cette représentation numérique ? En fait, c’est parce que ce qui est intéressant derrière, c’est la vision qu’en a votre ordinateur. Alors, en général, on écrit dans la formulation au-dessus pour les êtres humains normaux, et puis pour les ordinateurs, on l’écrit comme c’est en-dessous. Pourquoi c’est intéressant de savoir que ça, ça n’est que la représentation simplifiée d’un entier, parce qu’une décision de routage, ça se fait avec des opérations aussi bêtes que « plus petit que » et « plus grand que ». Donc, mathématiquement ça met en jeu des notions extrêmement puissantes qui sont en général enseignées vers le CE1.
Si l’adresse de la destination est plus grande que ça, et plus petite que ça, alors il faut faire suivre à lui.
On est bien d’accord, les ordinateurs ne manipulent que des chiffres, donc un interlocuteur, ça a un numéro. Une route c’est donc quelque chose d’assez simple : pour les adresses de tant à tant, c’est par là, pour les adresses de tant à tant, c’est par là. C’est même un protocole de routage que vous avez l’habitude d’appliquer. Ben oui, vous sortez d’une station de métro sur les boulevards parisiens, vous regarderez, à pas mal d’endroits, sur les plaques signalétiques des rues, il y a écrit le nom de la rue, et il y a écrit, pour les numéros de tant à tant c’est par là, numéros tant à tant, par là. C’est bien exactement la même chose que vous faites.
Un petit peu de vocabulaire.

Alors ça [premier point], juste tout seul, selon le point de vue qu’on en a, c’est une adresse sur le réseau Internet, qui peut être soit la destination, soit la source d’un paquet, soit un des intermédiaires de transport. Ça [second point], techniquement, c’est un préfixe, souvent on appelle ça une route, en fait ce n’est pas tout à fait vrai, c’est vraiment un préfixe, ça désigne une plage d’adresses. Ça [troisième point], dans l’exemple que j’avais tout à l’heure, c’est la passerelle, c’est-à-dire c’est la personne à qui on va transmettre les données pour qu’elle les transporte en notre nom, ce qui dans le mécanisme postal serait l’adresse du bureau de poste d’à côté.
Une BiduleBox, par exemple comme vous avez chez vous, c’est un routeur, ce n’est qu’un routeur, c’est un des carrés de mon dessin de tout à l’heure, qui a une passerelle, qui est celle du FAI, qui a deux adresses en général et qui a trois routes.
Un gros routeur, c’est-à-dire un vrai routeur comme un des carrés du milieu quoi, pas comme celui qui est chez vous, ça a facilement 150 passerelles et à peu près 300 000 routes ou 300 000 préfixes, ça a des routes sur 300 000 préfixes.
Comment ça se matérialise ? Comme ça.
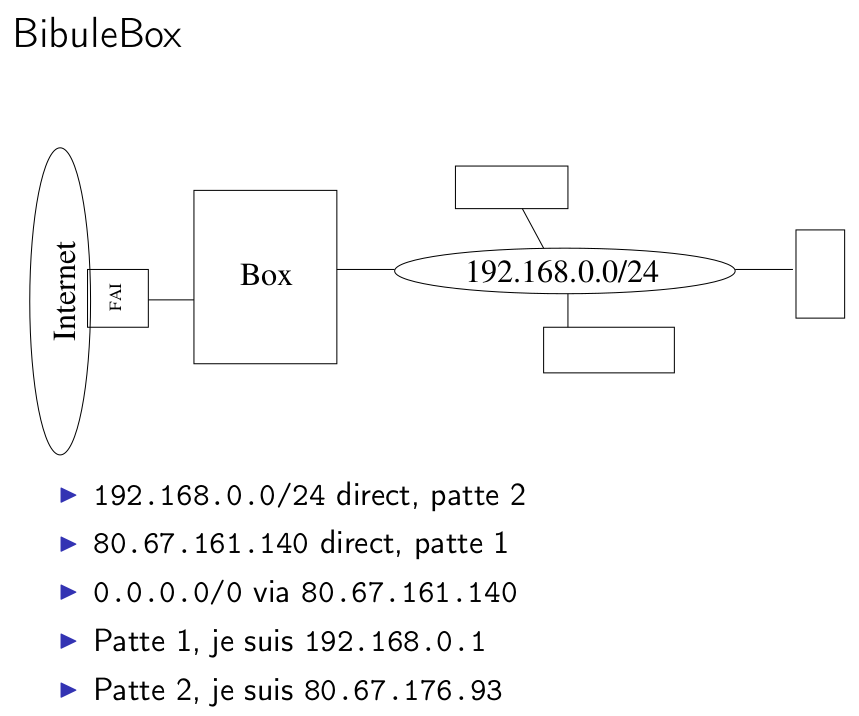
Il y a le réseau qui est chez vous, les trois machines sur la droite étant ce que vous voulez que vous avez chez vous de relié à Internet : le PC de bureau, le portable, l’iPhone, l’imprimante, la machine à laver, ce que vous voulez, on s’en fout. C’est le machin qui est relié chez vous. La Bidulebox, le routeur du FAI et sur le côté gauche : le vaste Internet. Vous savez là où il y a tous les nazis, les pédophiles. C’est celui-là l’Internet. Des fois, il est de l’autre côté aussi mais chez moins de monde.
Bien !
Cette machine, la box, c’est elle qui m’intéresse, simplement parce que c’est le routeur et que moi je veux vous expliquer comment se route tout ce fatras.
Cette boîte, elle a une première route qui lui dit : si tu as un paquet qui est à destination de 192.168.0.0/24, tu y es connecté de manière directe, c’est sur ta patte numéro deux, celle qui est à droite. Ensuite, elle a une deuxième route qui lui dit : il y a un interlocuteur, et un seul, que tu sais joindre, parce qu’il est au bout de ta patte numéro un. C’est le routeur du FAI. Et puis enfin, il y a une route qui lui dit : pour toutes les adresses de 0 à quatre milliards, t’enverras à pépère à gauche, là. D’accord ? C’est ce qu’on appelle une route par défaut. Ça veut dire que dans ce mécano-là, la boîte est capable, en voyant un paquet, sans savoir d’où il vient, juste en regardant où il va, de décider s’il faut l’envoyer sur la patte de droite ou sur la patte de gauche. En général, c’est assez simple : ce qui arrive sur la patte de droite va plutôt aller à gauche. Ce qui arrive sur la patte de gauche devrait plutôt aller à droite. C’est pas complètement systématique mais c’est presque ça.
Bien. Donc ça c’est du routage statique. C’est-à-dire qu’en fait chaque nœud du réseau connaît les adresses précises de ses voisins et par quel voisin il faut passer pour joindre quel autre bout du réseau. Maintenant, sur ce mécanisme, pour vous donner une petite idée : c’est comme si en vous promenant dans la rue, à chaque coin de rue, il y avait un panneau dans chacune des directions vous listant la totalité des destinations possibles. Pas juste les grands choix, je veux dire Marseille par là, Paris par là. Non non, ville par ville, rue par rue, toutes les adresses sur un panneau. On sent bien qu’à chaque fois que quelqu’un va donner un coup de tractopelle dans une rue quelque part, il va falloir mettre à jour un nombre de panneaux considérable. C’est ce qu’on appelle le routage dynamique.

Pour ça, le premier morceau dont on a besoin, c’est de nommer les réseaux. Donc le nom d’un réseau, c’est ce qu’on appelle son AS (Autonomous System), c’est le numéro de l’opérateur, puisqu’on reste dans de l’informatique, donc ils ont tout numéroté. Une route, le calcul de routage dynamique, se fait simplement parce que deux routeurs discutent. Et ils se racontent des histoires qui ressemblent à : « Je sais joindre tel préfixe, en trois sauts, via tel AS, tel AS, tel AS ». Et les routeurs passent leur vie à se raconter ça et à se dire l’un à l’autre : « J’ai une nouvelle route pour joindre machin, c’est un poil plus court, faudrait passer par là » ; « J’ai une nouvelle route, moins bonne parce qu’il y a un truc qui a sauté et donc maintenant il faut passer par là et c’est plus long », etc. Donc, ils passent leur vie à se raconter ça et à l’apprendre. C’est-à-dire qu’un routeur qui est connecté à cinq autres, apprend les 300 000 routes de la part des cinq routeurs et puis pour chacune de ces 300 000 routes, va comparer les 5 exemplaires et choisir celui qu’il juge le meilleur, soit parce que c’est plus court, soit parce que là-bas l’herbe est plus verte, soit… Il y a 1000 raisons possibles.
Alors, si je garde une symbolique qui va revenir dans plusieurs transparents : on va supposer que les bidules ronds, parfois à forme ovale sur certains dessins, sont des réseaux. Donc ça correspond à un AS, c’est-à-dire que typiquement vous allez avoir, Free, Orange, Neuf, FDN, Google, etc … Des réseaux, qui sont interconnectés entre eux et donc il y a au bord de ces réseaux un certain nombre de routeurs qui sont connectés avec les réseaux d’à côté, et sur lesquels on se raconte « Moi je sais joindre Google en quatre sauts via Orange, alors que lui il sait joindre Google en 7 sauts via Free etc. ». Voilà à quoi ressemble le plat de nouilles, si nos neuf opérateurs se retrouvent présents dans la même salle. Il y a un nombre d’interconnexions qui est assez hallucinant. Pour vous donner un ordre de grandeur : dans une salle machine, d’usage international, comme il y en a deux ou trois à Paris, on a couramment une centaine d’opérateurs. Je vous laisse imaginer la taille du merdier, sachant que sur Internet, toujours pour vous fixer des ordres de grandeur, il y a à peu près 40 000 opérateurs.
Donc voilà à quoi ressemble ce qu’on peut faire de pire comme système d’échange avec seulement neuf opérateurs présents, c’est-à-dire une petite salle machine de province.

Ça c’est beaucoup plus simple à établir, ça porte un nom : c’est un nœud d’échange.
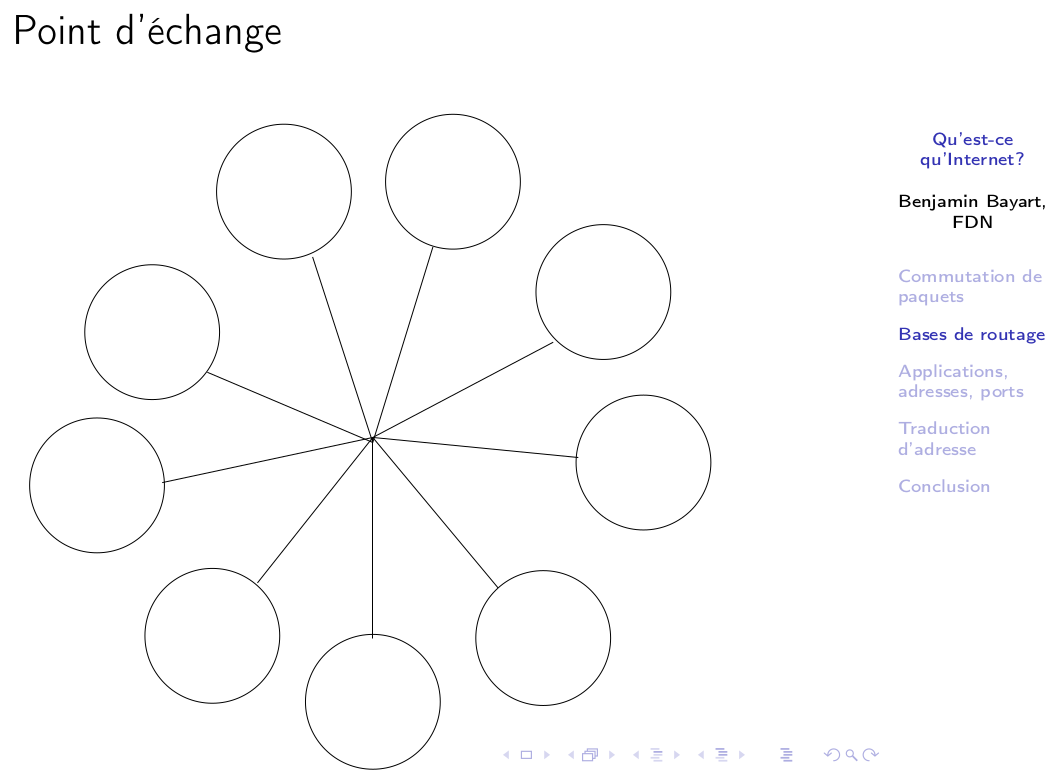
Donc, quand vous entendrez parler sur Internet de nœud d’échange, de GIX (Global Internet eXchange) ou de points de peering, c’est bêtement ça. C’est-à-dire quand on est plus de deux opérateurs dans la même salle, plutôt que de tirer des liens dans tous les sens et de faire des plats de nouilles avec des câbles réseaux, on met un switch au milieu et tout le monde se branche sur le même switch. Ça permet, l’air de rien, de se raconter un très grand nombre de routes, avec un très petit nombre de câbles.
Maintenant qu’on a ces quelques bases, on va pouvoir essayer de se poser un petit peu de vocabulaire et pour le coup, ça ce sont des mots, si vous essayez de suivre par exemple les vidéos du colloque qu’il y avait hier à l’ARCEP sur la neutralité des réseaux, qui est un des enjeux politiques majeurs, vous risquez de croiser ce genre de mots-là, qui ont été lâchés en supposant que tout le monde savait et qui ne sont pas forcément clairs.

Ce qu’on appelle une interconnexion, c’est simplement un lien entre deux opérateurs. Chacun des opérateurs gère son propre réseau, c’est-à-dire son petit bout d’adressage Internet, comme il a envie, avec des routes statiques ou avec des routes dynamiques. Il gère son petit bout de réseau avec ses petits bouts de routeurs, comme il veut. Deux opérateurs sont interconnectés quand ils ont établi un lien entre eux et que sur le lien ils s’échangent des routes. Ils se disent « Moi je sais aller là », « Moi je sais aller ailleurs, je sais y aller par telle route, qui coûte tant », etc., etc.
Il y a donc une des notions clef quand on veut comprendre le routage d’Internet, qui est de comprendre que chacun annonce des routes et que chacun apprend des routes. En particulier, un AS, un réseau, on sent bien que pour que le merdier marche, il faut un point de départ. Parce que j’interconnecte deux routeurs, chacun connaît 300 000 routes et puis ils vont se les échanger et décider de faire un partage, en fait. C’est-à-dire que le routeur de droite va décider que, sur tout le trafic qu’il envoyait précédemment ailleurs, maintenant il y a telle partie qu’il va plutôt envoyer à son voisin de gauche parce qu’il a de meilleures routes. On sent bien que ça marche une fois que le système est établi. On sent bien aussi que ça ne démarre pas : je prends deux routeurs, je les sors du carton, je les branche, je les allume… Ils les ont trouvées où, les 300 000 routes ? Il manque l’étincelle initiale. En fait, chaque routeur commence par annoncer - quand il se lève le matin, il se réveille, on vient de l’allumer, il ne sait rien - il sait au moins une chose, il sait qui il est et où il est. Et donc, il annonce à tous ses voisins : moi je suis l’AS numéro tant et je sais joindre en zéro saut, puisque c’est chez moi, telle plage d’adresses, telle plage d’adresses, telle plage d’adresses. Et donc, immédiatement tous ses voisins savent : « Tiens, ces trois nouveaux préfixes, qui n’existaient pas avant, maintenant se joignent en passant par tel câble ». Et tout ça se réplique, et se répète, et se ré-annonce à l’ensemble des voisins.
Ce qu’on appelle du peering, c’est quand deux opérateurs sont interconnectés et ne s’annoncent que leurs routes locales. C’est-à-dire, Free est connecté à Orange, Free annonce à Orange : « Toutes les routes pour me joindre moi, toutes ces routes-là sont moi. Ces ensembles d’adresses-là forment la totalité de mon réseau tu peux me les envoyer » et Orange annonce à Free : « Ces adresses-là sont moi, tu peux me les envoyer » et ils ne s’échangent que ces routes-là. En règle générale, le trafic qu’on s’échange en peering est gratuit. C’est-à-dire qu’en fait, les deux opérateurs se retrouvant voisins géographiquement, ils ont tout intérêt à tirer un câble une bonne fois pour toutes entre eux deux et à faire passer par ce câble-là tout le trafic.
Ce qu’on appelle du transit : c’est assez facile, ça vient du sens du mot transit en fait, c’est quand deux opérateurs s’annoncent des routes qui ne sont pas les leurs. C’est-à-dire quand j’annonce à mon voisin : « Non seulement ces routes-là c’est chez moi, mais en plus je te donne tout ce que j’ai, moi, comme routes pour joindre le reste d’Internet ; tu jugeras de celles que tu préfères et donc du trafic que tu voudras m’envoyer. Ce trafic n’est pas à destination de mon réseau, il est à destination de plus loin. Et donc ce trafic, que tu m’enverras et qui n’est pas à destination de mon réseau, va transiter sur mon réseau, pour arriver à la sortie ». Typiquement, entre votre ordinateur et l’ordinateur de quelqu’un qui habite aux États-Unis, il y a probablement trois ou quatre opérateurs intermédiaires. Ces trois ou quatre opérateurs intermédiaires font bien du transit. Le paquet qui circule n’est pas à destination de chez eux, ils le transportent pour compte de tiers. Ça, bien entendu, c’est systématiquement facturé.
Ensuite, il faut comprendre qu’il y a un élément clef pour les opérateurs - ces temps-ci ils sont en train de changer d’avis sur la signification qu’il a - qui est la symétrie du trafic. On sent bien que quand on crée un lien entre deux réseaux, la quantité de données envoyées dans chaque sens n’est pas symétrique. Typiquement, si vous créez une interconnexion entre un fournisseur d’accès qui est, mettons, Orange et un fournisseur de contenus, mettons YouTube, le trafic va quand même essentiellement aller de YouTube vers Orange, et marginalement dans l’autre sens. Ce point-là est, techniquement, sans le moindre intérêt mais est un argument de poids dans les négociations commerciales. En général, on considérait, jusqu’il y a quelques années, que quelqu’un qui émet beaucoup de données, est un partenaire intéressant parce que ça fera toujours ça de moins à aller récupérer, et donc on cherchait à s’y connecter. Depuis à peu près un an, les opérateurs sont en train de changer d’avis et il sont en train de dire que finalement, quelqu’un qui émet beaucoup de données, c’est juste un parasite, il fait rien qu’à se servir du réseau, donc ils aimeraient bien, soit qu’il paye, soit qu’il arrête. Donc voilà, il y a des bouts de négociations politiques et commerciales derrière, qui sont non triviaux. Enfin, il y a évidemment un point clef qui est le volume. C’est-à-dire qu’un lien sur lequel on va échanger trois mails par jour, ça n’a pas du tout du tout du tout la même tête qu’un lien sur lequel on va faire circuler des centaines de millions de vidéos tous les jours, et c’est en général un point clef. C’est-à-dire que deux opérateurs, même s’ils ne sont pas encore géographiquement voisins, qui s’échangent des quantités astronomiques de données, ont intérêt à devenir voisins, ont intérêt à, même s’il faut faire des trous dans les trottoirs, passer un câble entre eux deux. Et donc si vous voulez comprendre ce qui peut se raconter sur du réseau, dans la presse spécialisée, si vous voulez faire une lecture un peu fine de ce que Free peut dire comme mal sur YouTube, ou de ce qu’Orange peut reprocher à tel ou tel fournisseur dans la presse, ou si vous voulez comprendre par exemple la guerre qu’il y a eu entre Neuf et Dailymotion en 2007, il vous faut comprendre qu’ils sont en train de parler de peering, qu’ils sont en train de parler de trafic asymétrique et qu’ils sont en train de parler de volumes énormes et que ce sont les trois points clefs pour comprendre de quoi il s’agit.
Bien. Si j’essaie de résumer un petit peu ce que je vous ai dit sur le routage et qui était a priori non simple :

Le premier morceau à bien retenir, c’est qu’on route des paquets, toujours. C’est-à-dire que quand on essaie de vous faire croire que pour regarder de la vidéo, il faut du réseau d’une qualité différente de ce qui faut pour lire du mail, ben c’est pas vrai. C’est-à-dire que ça transporte des paquets, ça ne les transportera pas plus vite ni moins vite et effectivement, ça crée de vraies difficultés, c’est-à-dire que pour regarder de la vidéo, il y a besoin d’un flux continu, or on crée un flux continu en transportant des petits bouts. Et vous verrez, c’est très compliqué. En particulier, un réseau qui fonctionne par paquets, si à un endroit, à un moment, il sature, la seule chose raisonnable à faire, c’est de jeter le paquet. Et on sent bien que dans une vidéo, si on jette un paquet en plein milieu, ça va faire un trou dans le film. Et donc de là viennent tout un tas de stratégies sur « Est-ce que je veux absolument voir le film ? », auquel cas le bout de paquet que je n’ai pas reçu, je vais demander à ce qu’on me le renvoie, pour compléter le flux. Si par exemple, je suis en train de télécharger un film, ou c’est par exemple ce qui explique que sur un navigateur, quand vous regardez une vidéo, il commence par bufferiser : avant de vous montrer la vidéo, il va télécharger les 5 premiers mégaoctets, comme ça il a trente secondes d’avance, et le temps que vous regardiez les trente premières secondes, il va télécharger le reste. Si à un moment il y a un paquet qui se perd, ce n’est pas grave, il aura le temps de le redemander sans bloquer. Internet est fait comme ça.
Ce que je veux que vous compreniez aussi, c’est que l’ensemble est bête à manger du foin. Un routeur, c’est quelque chose qui est capable de faire deux opérations mathématiques, qui sont ‘inférieur’ et ‘supérieur’, pour décider de l’endroit où ça doit aller. C’est tout. Il le fait plusieurs milliards de fois par seconde, c’est entendu, mais il ne fait que ça. Ça n’a rien de compliqué, et c’est ça qui fait qu’Internet fonctionne. Ce qui fait que l’on n’a pas été capable, sur les réseaux précédents, d’amener chez tout le monde un petit routeur, c’est que ça coûtait trop cher. Un routeur de téléphone (ce qui vous aurait permis d’avoir autant de lignes de téléphone que vous auriez voulu chez vous), c’est épouvantablement compliqué à fabriquer, car il faut que ça comprenne toute la topologie du réseau et que ce soit capable de construire un circuit. Par contre un routeur qui commute des paquets, c’est bête à manger du foin, un CPU de montre à quartz suffit à faire un routeur élémentaire. C’est ce qui fait qu’on peut fabriquer pour trois sous des routeurs qu’on met chez tout le monde. Et c’est ça qui a permis à Internet de se développer et qui a empêché des développements aussi massifs sur les autres réseaux. Donc techniquement, c’est extraordinairement simple.
Ensuite c’est absolument universel : c’est-à-dire que les données qu’on transporte peuvent être n’importe quoi, peuvent être des questions ou des réponses, il n’y a pas de différence. Dans la mesure où on ne transporte que des paquets, juste en voyant passer le paquet, il n’y a pas moyen de savoir qui est serveur et qui est client là-dedans. On sait juste qu’il y a un paquet qui va dans tel sens : est-ce que c’est la commande, ou est-ce que c’est le colis avec la livraison, on ne sait pas. Et ça, c’est fondamental à comprendre. Ce qui a fait le succès d’Internet, c’est le fait qu’il est extraordinairement simple à écrire.
Enfin, là-dedans, tout cela est symétrique. Si vous regardez dans les différents dessins de réseau que je vous ai passés jusque-là et dans l’explication sur comment fonctionne le routage, il n’y a pas de nature d’adresse, c’est-à-dire qu’il n’y a pas des adresses d’un type donné qui sont les adresses des serveurs, et des adresses d’un type différent qui sont des adresses des clients. Le réseau transporte des paquets. En fait, quand je vais consulter une page web, il y a des paquets qui partent de chez moi pour dire au serveur web : « Je veux telle page », et des paquets qui partent du serveur web et qui viennent chez moi pour dire : « Tiens, la voilà, je l’ai découpée en 37 paquets, voilà les paquets 1 à 12 ». Le réseau, s’il se contente de faire son travail de routage, ne sait pas ce que c’est et ne sait pas qui est client et qui est serveur. Ce sont des notions qui ne le concernent pas. C’est quelque chose de très particulier à Internet. Typiquement, quand vous regardez un réseau à commutation de circuit, on sait très bien qui est à la demande de la création du circuit, et qui est la destination. Donc du coup, on sait celui qui est le client, celui qui demande, et qui est le serveur, celui qui est la destination. Ils ont même parfois des connexions différentes. Si vous regardez un réseau dont vous avez l’habitude et qui est un réseau à commutation de circuit, sur le réseau d’eau, on fait une différence assez nette entre les gens qui injectent de l’eau dans le réseau et les gens qui en sortent. Ce n’est pas le cas sur Internet. Donc, le réseau est fondamentalement et essentiellement symétrique. Même si les débits peuvent être asymétriques, il n’y a pas de différence de nature entre l’adresse IP qui est chez vous et l’adresse IP qui est à l’autre bout, et il n’y a pas de différences structurelles entre un routeur et un autre.
Enfin, il y a un point à comprendre, qui est que l’on peut utiliser ce protocole de routage pour router n’importe quoi. Si je prends 4 ordinateurs, que je les raccroche à un switch et que je fais les petites configurations qui vont bien avec les petits bouts de table de routage qui vont bien, j’ai créé un réseau qui est routé, qui utilise le protocole IP, qui utilise les tables de routage comme on a vu avec machin.truc.bidule.chose/12. Tout ça c’est un réseau, et ce réseau n’est pas Internet. C’est juste un réseau routé avec ce protocole-là. Ce qui fait Internet, c’est simplement les 40 000 réseaux routés par ce protocole-là, qui sont interconnectés entre eux, et qui pour pouvoir s’interconnecter entre eux ont été obligés de respecter un nombre de règles très simples, dont par exemple, le fait d’éviter les doublons. Je ne sais pas si vous avez déjà réfléchi à comment marcherait le téléphone si deux personnes avaient le même numéro de téléphone. Quand je compose le numéro, j’appelle qui ? Un vrai problème ! L’unicité de l’adresse est quelque chose d’indispensable sur un réseau. Et donc, le réseau IP sur lequel tout le monde s’est mis d’accord sur l’unicité des adresses et donc sur le fait de ne pas utiliser les adresses du voisin quand on construit son petit bout de réseau personnel, c’est ça qu’on appelle Internet. Tout le reste, tous les autres réseaux IP, et il en existe énormément d’autres, sont des réseaux privés. Par exemple, le réseau qui existe entre mon ordinateur et mon imprimante, il utilise certes des adresses IP, mais pas des adresses publiques, pas des adresses IP qui m’ont été officiellement attribuées, et donc ça forme un réseau privé. En particulier, ce réseau continue à fonctionner quand je coupe l’accès à Internet chez moi.
Bien.
Ce que je veux que vous compreniez aussi, c’est que dans les questions de routage, quand il s’agit de savoir comment sont transportées les données, à aucun moment on a spécifié la nature du paquet. Que ce soient quelques millisecondes de voix, que ce soient quelques lignes d’une page Web, que ce soit une requête DNS, que ce soient quelques millisecondes de jeu dans un jeu vidéo, c’est un paquet de données brutes auquel le réseau ne comprend rien. Et en fait, basiquement, ce n’est pas son problème.
Maintenant, si on cherche à utiliser cette infrastructure pour faire de la communication, on constate qu’une machine peut parler avec plusieurs autres, c’est-à-dire : une machine peut parler avec plusieurs autres, je peux consulter deux pages Web en simultané, et un serveur Web peut être consulté par plusieurs personnes en simultané. Ça vous paraît évident, ça ? Vous pouvez être plusieurs sur Facebook en même temps.
De la même manière, n’importe quelle machine sur le réseau peut être soit client, soit serveur, ça ne change rien à la nature du réseau. Du coup, sur ma machine qui est en train d’émettre des pages Web à destination de 12 personnes pendant que moi je suis en train de surfer sur 15 sites, comment on fait le tri des paquets qui rentrent et qui sortent ? Parce que des paquets, elle en reçoit plein, elle en émet plein, comment elle sait quel paquet correspond à quelle page ?
La bonne solution, c’est comme toujours en informatique, de rajouter un numéro. C’est ça ce que l’on appelle le numéro de port. En fait, c’est simplement un identifiant de la connexion. C’est juste : la machine indique telle connexion porte tel numéro chez moi.

Ça s’explique mieux sur un exemple. Voilà à quoi va ressembler une requête Web : une URL qu’on veut aller chercher, je tape ça dans mon navigateur, voilà ce que ça donne sur le réseau.

Ma machine émet depuis le port numéro n’importe quoi, quand on émet on prend un port au hasard, à destination du serveur D, D comme DNS, sur le port 53 une requête qui dit : « Où habite wawawa.fdn.fr ? ». Je vous laisse imaginer que le serveur DNS, sur le port 53, des requêtes, il en reçoit en permanence. Il en reçoit des milliers par seconde. S’il n’a pas le numéro de port pour savoir à qui il doit répondre, il va envoyer la réponse certes sur la bonne machine, mais pas forcément à la bonne question. C’est-à-dire quand vous interrogez votre DNS, si quand vous lui demandez où est Facebook, il vous répond l’adresse de Wikipédia sous prétexte que dans l’onglet d’à côté vous avez demandé où est Wikipédia et que là il a répondu l’adresse de Facebook, ça va très vite mal se mettre. Donc lui, il répond : « Il habite à telle adresse » que nous appellerons W pour la suite, W comme Web.
D’où, connexion suivante : la même machine depuis un autre port, écrit à M. W sur le port 80 pour lui dire : « Donne-moi donc minitel.avi » et M. W va répondre « Tiens, voilà, gaffe c’est long. Prévoir plusieurs paquets, à peu près 600 000 ». Voilà, une requête web ça ressemble à ça.
Il n’y a pas de différence structurelle importante entre le paquet réponse du serveur DNS et le paquet question pour le serveur Web. Vu du réseau de transport, c’est la même chose.
Une évidence cependant : autant le numéro de port du client n’a aucune espèce d’importance - il est important pendant la durée de la connexion pour dire : c’est bien dans le cadre de telle connexion que telle réponse a un sens, mais il n’a pas d’importance a priori. Par contre, le numéro de port du serveur est vital. Parce que si, dans mon exemple précédent, le serveur Web et le serveur DNS sont la même machine, si je parle sur le port 53, je pose une question sur les noms de domaine, si je parle sur le port 80, je pose une question sur le serveur Web. Donc, il est important que les numéros de port des applications pour les serveurs soient fixés. Et donc, il y a tout un tas de numéros de port qui sont standardisés.
Alors, un des moins connus des internautes débutants, c’est le 53, qui est pourtant le plus important parce que c’est le DNS, et si vous enlevez le DNS, vous êtes obligés de taper les adresses des machines. C’est vite rébarbatif. Le 80, que beaucoup de gens connaissent, c’est le Web. Le 443, que beaucoup de gens connaissent qui est Web chiffré. Le 25 qui est l’envoi du mail, ce que peu de gens pratiquent. Le 110 qui sert à relever une boîte aux lettres, ce qui est déjà plus fréquent. Et puis j’en ai choisi un autre, il y en a quelques centaines des ports standardisés, le 179 : moi je l’aime bien, parce que c’est le BGP, c’est-à-dire qu’en fait, c’est le numéro de port de l’application utilisée par les routeurs pour se raconter leur vie. Quand deux routeurs discutent entre eux, pour se raconter « Moi, je connais une route vers tel réseau via tant de sauts qui passe par l’AS machin, l’AS truc, etc. », c’est sur le port 179. C’est une application comme une autre, c’est pas plus malin ou pas plus crétin que du mail ou du Web. Le protocole d’échange entre deux routeurs, ce qui permet de dire “j’ai une meilleure route maintenant pour joindre telle cible”, c’est une application comme une autre.

Bien.
Alors là, on va attaquer de la technique qui est assez pénible. Pour le moment, je vous ai expliqué comment on faisait pour faire discuter un client Web avec un serveur Web et que le tout soit routé dans le milieu, si possible sans se perdre et en démêlant les fils à la sortie, sachant que tous les paquets ont été transportés en vrac. C’est-à-dire qu’ils sont probablement arrivés dans le désordre - ils sont a priori partis dans l’ordre, à moins de le faire vraiment complètement exprès, les ordinateurs émettent plutôt les paquets dans l’ordre. C’est juste les aléas du réseau qui font que ça arrive plutôt dans le désordre. Exactement comme quand vous partez à 30 du même endroit, vous n’arriverez pas forcément dans l’ordre dans lequel vous êtes partis.
Il y a un point là-dedans quand même qui est important, c’est qu’on a bien vu cette notion de public/privé. Si je regarde ce que c’est qu’un réseau à la maison, basiquement il y a un ordinateur ; pour peu que je ne sois pas complètement célibataire, il y a deux portables, un chacun ; pour peu que nous soyons des gens modernes avec des iPhones ou équivalent, il y a deux téléphones qui veulent aussi une adresse, et puis comme il arrive d’écrire, il y a une imprimante. Bien. Comme on n’a pas acheté 5 imprimantes, il n’y en a qu’une et on la partage en réseau. Tout ça, ça fait 6 adresses.
Sachant qu’il y deux milliards d’internautes, une multiplication de tête rapide, ça fait 12 milliards d’adresses. Il n’y a que 4 milliards d’adresses possibles sur Internet, à l’heure actuelle. Ça ne rentre pas ! Je suis formel. Hormis pour les très grandes valeurs de 4, 12 ça ne rentre pas dans 4.

Comment on traite ça ? Alors en fait, on le traite à partir d’adresses qui sont interdites sur le réseau. C’est-à-dire qu’il y a des blocs d’adresses qu’on n’a pas le droit d’avoir. Exactement comme il y a des numéros de téléphone que vous n’avez pas le droit d’avoir. Vous chercherez : des numéros de téléphone qui commencent par 00, il n’y en a pas, pour cette raison simple que 00, c’est ce qui sert à faire l’international : c’est réservé. Les numéros de téléphone qui commencent par 99, il n’y en a pas. Voilà, il y des tas de plages de numéros de téléphone qui ne sont pas autorisées ; ou qui sont réservées à des usages internes. Eh bien de la même manière, il y a des plages d’adresses qui sont interdites sur le réseau public. C’est-à-dire que n’importe quel routeur qui participe à Internet sait que s’il y a un paquet qui est « en provenance de » ou « à destination de » une adresse là-dedans, il doit le jeter ; parce que ça ne correspond à rien.
Ces adresses sont dites privées. Qu’on soit bien d’accord, elles ne sont pas abimées, c’est des adresses normales, c’est juste qu’on a décidé par convention que celles-là on ne les distribuerait jamais à personne. Donc vous pouvez être certain qu’aucun ordinateur réellement connecté à Internet n’a cette adresse-là.

Et c’est ce qui fait qu’on utilise ces adresses-là chez nous. Par exemple, pour faire mon réseau interne, pour que mes portables puissent discuter entre eux et puissent discuter avec l’imprimante. Comme je suis sûr que personne sur Internet n’a cette adresse-là, je peux tranquillement faire mon petit réseau chez moi, ça ne posera pas de problème, je ne vais pas masquer les adresses de quelqu’un.
Par contre, il y a un vrai problème. Alors ça marche très bien, ça se monte très facilement, un petit réseau interne avec un bloc d’adresses qu’on a choisi. Sauf qu’évidemment, ça ne permet pas de parler en public puisque si j’émets une requête, elle aura comme adresse source mon adresse privée, et que le premier routeur un petit peu sérieux sur Internet qui voit passer ça, il va dire c’est de la merde, c’est une adresse interdite, je jette. Et surtout, comme ces adresses n’appartiennent à personne, les routes ne sont pas annoncées, et donc, même si le paquet atteignait sa destination, la réponse ne pourrait pas revenir. Il n’y a pas de routes vers ces adresses-là. Donc, il n’y a pas moyen de parler en public.

Alors je vous propose qu’on regarde, en essayant de ne pas se faire trop mal à la tête, comment se passe une question, bêtement une requête sur un serveur Web, depuis une adresse IP privée, et ce que fait votre BiduleBox quand elle vous permet d’accéder à Internet.
Donc la question ressemble à ça : le paquet qui est émis par votre machine, il vient de 192.168.0.42 sur le port n’importe quoi et il est à destination d’une adresse IP publique sur le port 80. Si je ne me trompe pas, de mémoire, ça doit être l’adresse IP du serveur Web de FDN, ça. Bien…
La bidulebox, elle fait : « Je note, je prends un numéro de port à moi, au hasard, et je note dans mes petites tablettes, 6734, en vrai, c’est M. 0.42 port : tant ». Et donc le paquet qui venait du côté interne à destination de l’extérieur et donc qui avait comme adresse source une adresse privée, est rectifiée. C’est-à-dire qu’en fait, on efface l’adresse source et on en met une autre. Et en fait, on met la vraie adresse IP de la bidulebox, qui est une IP publique, sur le numéro de port qu’elle vient de réserver. Et elle a bien noté dans un coin, ce numéro de port, c’est celui que j’ai utilisé pour tel numéro de connexion en retour.
Ce paquet là, il a comme adresse source, une adresse publique, et comme adresse de destination une adresse publique. Il peut donc parfaitement être transporté sur Internet, il ne pose plus de problème. Donc Internet transporte, ça va jusqu’au serveur Web qui réfléchit longuement à la réponse, et il envoie sa réponse. Pas spécialement futé le serveur Web. Il répond à la personne qui lui a parlé.
Donc ce paquet là quand il est reçu par la bidulebox, ça dit que c’est à destination de la box, du routeur lui-même. Pas du tout à destination de la machine qui a demandé la page. C’est pour ça que tout à l’heure, il a pris des notes. Donc, il regarde dans ses notes, il voit 6734 c’est pour qui ? 6734, j’avais noté c’est pour machin ; je lui renvoie.

On est bien d’accord, ce mécanisme là, il n’est possible que sur de la commutation de paquets. Sur de la commutation de circuit, il aurait fallu établir un circuit, continu, entre une machine qui n’a pas d’adresse, et une machine qui a une adresse à l’autre bout. C’eût été compliqué.
Eh bien évidemment, une fois que j’ai fait ça, le paquet est à destination de la bonne machine qui recevra donc, qui aura vraiment l’impression de recevoir une vraie réponse venant du monde du dehors. La machine n’a pas notion que son message a été modifié, c’est-à-dire qu’on a changé le destinataire de la lettre, changé l’expéditeur, tout bricolé dans le milieu et pourtant ça arrive au bon endroit.
Ça, c’est ce que fait votre routeur chez vous quand il permet ce qu’on appelle du partage de connexion. Lui, il a une vraie connexion à Internet, et la prête aux machines internes.
Un interlocuteur dans la salle : Est-ce qu’il y a une différence entre un routeur et un modem ? La BidulebBox, c’est un routeur ?
Benjamin Bayart : C’est un routeur, oui.
Dans la salle (même interlocuteur) : C’est quoi un modem ?
Benjamin Bayart : Une carte réseau.
Dans la salle (même interlocuteur) : D’accord.
Benjamin Bayart : Un modulateur/démodulateur, c’est donc, comme son nom l’indique, un merdier qui gère la ligne physique. C’est tout. Lui, il n’a pas d’adresse IP. Un modem, c’est juste quelque chose qui gère la partie traitement du signal.
Dans la salle (même interlocuteur) : Donc, dans une BidulebBox, il y a un modem et un routeur ?
Benjamin Bayart : Il y a un modem et il y a un routeur. C’est même pour ça que souvent, ça s’appelle un modem/routeur. En fait il y a bien deux morceaux très distincts.
Bien. Donc ça ça marche. Ça marche au sens où vous vous en servez tous les jours, ça vous permet d’aller sur le Web, en tant que client. Ça ne permet pas de stocker un serveur. C’est-à-dire que l’adresse IP ici, comme elle n’est joignable de nulle part, elle ne permet plus d’avoir de serveur Web. C’est-à-dire que ce petit artifice d’utilisation que vous avez chez vous, vous empêche d’avoir un serveur. Tant qu’on est sur ce mode de fonctionnement-là, vous ne pouvez, chez vous, que consulter des données qui sont à l’extérieur.
Vous ne pouvez pas permettre pour le moment à quelqu’un de l’extérieur de venir consulter des données qui seraient hébergées à cette adresse-là. C’est-à-dire sur le port 80 de la machine interne de mon réseau dont l’adresse est tant.
Ça, c’est ce que l’on appelle de la traduction en entrée.

C’est-à-dire que dans ma bidulebox, je rajoute une nouvelle règle qui dit à la box : à partir de maintenant, ce qui est pour moi à partir du port 80 est renvoyé à telle machine sur le réseau interne sur le même port 80.
Du coup, quand quelqu’un vient consulter le site Web qui est hébergé comme ça chez moi, on a le quelqu’un du dehors qui envoie sa requête vers l’adresse de la box port 80. Pourquoi port 80 ? Simplement parce qu’il a rentré le nom de domaine et que le navigateur tout seul, « Bah, c’est du Web donc port 80 ». La boîte, elle décide d’appliquer la règle, donc elle réécrit le paquet en disant qu’il est à destination de telle machine en interne. Ça, on sait joindre, le serveur peut répondre, et on voit ressortir un paquet qui est avec, comme source, ma machine locale qui a une adresse invalide, et comme destination, l’adresse IP publique qui a posé la question. On applique la même règle en sortie. C’est-à-dire qu’on dégage ce morceau-là (l’adresse privée) et qu’on remplace par l’adresse publique de la boîte ; et on obtient un paquet qui est parfaitement valide et qui peut partir sur Internet.
On voit donc que l’adresse IP publique qui avait posé la question, pensait parler à une machine, a au final parlé à une autre, mais a vu la réponse venir de la machine avec laquelle elle pensait parler. Donc, il y a quelqu’un qui joue du poker menteur au milieu de manière suffisamment propre pour que ça ne se voit pas. Maintenant, si on regarde un cas d’école pas complètement idiot, alors évidemment ça marche, seul défaut, je ne peux avoir qu’un seul serveur. Moi, j’ai plusieurs machines chez moi, comme ma BiduleBox n’a qu’un seul port 80 je ne peux avoir qu’un seul serveur Web.
Maintenant, on peut complètement imaginer que l’un d’entre vous, avec son ordinateur derrière sa BiduleBox, veuille parler au site web qui est derrière la mienne, de BiduleBox. Et donc, il faut traduire en sortie, puis retraduire en entrée, puis retraduire en sortie puis retraduire en entrée. L’exercice sera laissé à l’auditeur qui aime l’aspirine.

Ça fait très vite mal à la tête et on se demande assez rapidement comment deux machines qui sont à des endroits différents sur le réseau et qui pourtant ont la même adresse privée, peuvent discuter entre elles sans se marcher sur les pieds.
Ça, c’est quelque chose qui est très courant dans les réseaux. Le fait de traduire les adresses et de réécrire à la volée, etc. Ça vient essentiellement du manque d’adresses IP dans l’Internet qu’on connaît aujourd’hui. Les adresses IP qu’on écrit comme ça sous forme de quatre paquets de chiffres avec trois points, la prochaine génération, il y en a un petit peu plus, vraiment beaucoup plus. C’est-à-dire que c’est plusieurs milliards d’adresses à disposition de n’importe quel être humain. C’est vraiment beaucoup plus, en fait. L’ordre de grandeur est plus voisin du nombre d’atomes dans l’univers. Donc, ça permettra entre autres d’enlever tout ce fatras. Et donc de faire en sorte qu’on revienne à un adressage beaucoup plus simple.
Pourquoi est-ce que je vous ai embêté avec ça ? Parce que je veux que vous compreniez que déjà à l’heure actuelle, une communication qui a lieu entre vous et un serveur Web, elle subit un nombre de choses que la morale réprouve, assez violent.
En particulier, vous pensez que votre machine émet des requêtes à destination de, et qu’elle reçoit des réponses, et en fait, dans le milieu, ils sont plusieurs à avoir, à plusieurs reprises, effacé l’adresse d’expédition pour la remplacer par une autre, effacé l’adresse de destination pour la remplacer par une autre. Au final, ça marche ou pas mais globalement, vous n’y êtes pas pour grand chose. Il y a beaucoup de gens qui ont décidé de ce qu’ils faisaient de votre communication à votre place, là-dedans. Je ne dis pas que ce soit mal. Il se trouve qu’en moyenne, globalement, l’ensemble marche. Mais c’est quand même important, que le facteur réécrit l’adresse. C’est intéressant. Ce qui est intéressant, c’est de savoir qu’à l’heure actuelle, vous n’êtes pas capables, de manière simple, de le repérer. C’est ce qui fait par exemple que n’importe quel serveur peut se faire passer pour n’importe quel autre, sans que vous ne puissiez rien repérer. Tant que je reste sur des adresses au niveau du routage et du transport, n’importe quelle machine peut se faire passer pour n’importe quelle autre, vous ne verrez rien.
Question : Est-ce que le routeur garde le journal des adresses privées qu’il a utilisé ?
Benjamin Bayart : Ben, ça dépend quelle taille de routeur. La BiduleBox, elle peut s’amuser à essayer de garder un journal. Avec un disque dur d’une taille standard, on doit pouvoir garder des traces sur à peu près huit jours pour n’importe qui. Un vrai routeur sur du vrai réseau un peu plus poilu, non, là, pas moyen. Le routeur moyen qui voit passer 20 ou 30 millions de paquets par seconde, non, il ne va pas prendre des notes. C’est juste pas raisonnable. C’est-à-dire que lui, il lui faut un disque dur par minute, c’est trop cher. Donc, non, on ne sait pas. Et de toute façon, on ne pourrait pas se baser sur les traces : parce qu’il a pris les traces qu’il voulait, et bien évidemment, quand on fait quelque chose de malicieux, on évite de tenir un journal.
Hormis quelques espions qui se sont rendus célèbres dans des procès par le fait qu’ils avaient bien noté tout ce qu’ils faisaient, en règle générale, les gens sérieux, quand ils veulent faire des trucs malicieux, ils ne prennent pas de notes.
Bien, on rentre dans les 5% qu’il faut retenir. Si vous avez à peu près compris ce que c’est que du routage, vous avez compris que pour router un paquet, la seule information intéressante, c’est l’adresse destination. Le reste n’a aucune espèce d’importance. En particulier, le numéro de port, que ce soit le numéro de port source ou le numéro de port destination, n’intéresse pas le réseau. Pour un routeur, que ce soit une requête DNS, une requête Web à destination de Google ou de Youtube ou de mon blog à moi ou du blog de l’association ou du site Web de Sciences-Po, c’est bien pareil. C’est juste un paquet avec une IP destination, le numéro de port n’intéressera que la machine cible.
Une autre notion forte : quand on n’a qu’une adresse IP privée, on est un pur consommateur de contenu. On ne peut pas émettre sur la toile depuis une IP privée. Il faut nécessairement une IP publique. Je vous rappelle, n’importe quel ordinateur connecté à Internet, c’est basiquement, dans la même boîte, un émetteur radio et un récepteur radio. Assez voisin d’une CB. Vous recevez tout le monde et vous pouvez parler à tout le monde. À partir du moment où vous supprimez son adresse publique, vous avez un pur récepteur. Vous êtes passés d’un monde dans lequel vous pouvez vous exprimer, à un monde dans lequel vous pouvez écouter. C’est structurellement, fondamentalement différent.
C’est ce qui fait qu’à l’heure actuelle, par exemple dans l’internet mobile, il n’y a aucun des trois grands opérateurs qui fournissent des adresses IP publiques pour ces merdiers-là. Parmi tous les MVNO, il y en a un seul qui le fait et je ne donnerai pas son nom, je ne veux pas lui faire de pub. D’autant qu’il fait plein de trucs sales à côté.
Et donc il n’y en a qu’un et, a priori, vous n’êtes pas clients là-bas parce qu’ils ont très peu de clients.
Donc, il faut une adresse IP publique pour un serveur. C’est-à-dire que tant qu’on n’a pas une adresse IP publique, donc reconnue sur le réseau, donc joignable à tout moment sur le réseau, on n’est pas sur Internet. On est sur un réseau privé, qui passe par un intermédiaire pour accéder à Internet. L’intermédiaire en question étant, chez vous, votre BidulebBox, sur l’accès mobile, le gros routeur qui joue le rôle de BiduleBox de votre opérateur mobile ; et typiquement, dans une université, le routeur de l’université.
Enfin, le port réservé qui permet de savoir quel type de serveur on joint, n’est qu’une convention. Faire en sorte qu’un serveur Web ne soit pas sur le port 80, c’est à peu près 12 secondes de travail pour n’importe quel informaticien mauvais.
Faire en sorte que votre navigateur aille chercher une page ailleurs que sur le port 80, c’est juste une convention de notation dans l’URL. À la fin du nom de domaine, donc à la fin du www.fdn.fr au lieu de mettre /minitel.avi vous mettez :18/minitel.avi et votre navigateur, il ira demander sur le port 18 au lieu du port 80.
Donc, le numéro de port réservé, ça n’est véritablement qu’une convention de notation. C’est plus simple de la respecter, ça évite de se perdre, mais ça n’est vraiment qu’une convention.

Ce dont je parlerai dans la prochaine conférence, c’est essentiellement de ce qui circule là-dedans, de ce à quoi ressemble une requête sur une appli. Et je m’intéresserai évidemment à plusieurs types d’applis pour que vous ayez une idée de à quoi ressemblent les échanges.
Bien.
L’aspect plus intéressant, les points politiques là-dedans.
Un accès internet, c’est une adresse publique. Point ! Par définition. Le reste, c’est de l’accès à des choses numériques, mais ce n’est pas un accès à Internet.
Il y a un danger à interdire le Peer-To-Peer, c’est-à-dire les échanges directs d’un abonné Internet à un autre ; pas forcément des échanges de musique illégale ou de films pédos-nazis avec des animaux, simplement un échange de fichiers avec deux ordinateurs connectés au réseau public. C’est dangereux de l’interdire, parce que l’on crée une asymétrie. C’est-à-dire qu’on crée un réseau dans lequel certaines machines ne font qu’aspirer du contenu, et d’autres machines ne font que pousser du contenu. Et donc, on déstabilise l’ensemble du réseau. En particulier, par exemple, on empêche tout échange local.
On a également un vrai danger à multiplier l’usage de l’adressage privé. Tant que l’adressage privé est utilisé chez vous derrière votre BiduleBox, ça ne pose pas de souci majeur. Parce qu’en fait vous êtes toujours détenteur d’une adresse publique, qui est celle de la boîte. Et depuis laquelle vous pouvez émettre ce que vous voulez. Par contre, le fait d’avoir généralisé ça, par exemple dans l’Internet mobile, fait que vous ne pouvez plus émettre. En fait, l’accès mobile qu’on vous vend à l’heure actuelle, ne vous permet pas d’émettre des données. Et c’est en soi une limitation inacceptable. C’est exactement comme si on vous vendait de l’accès téléphonique où vous pouvez, soit appeler, soit être appelé, mais pas l’autre sens. Typiquement, c’est exactement comme si on vous vendait du téléphone où vous pouvez appeler les gens mais vous ne pouvez pas être appelé, parce que vous n’avez pas de numéro de téléphone. C’est très curieux, comme mécanisme. Et donc ça, ça crée un vrai danger, puisque ça crée artificiellement une centralisation de l’information.

Voilà, sur la partie réseau, j’ai fini et donc vous je vous propose qu’on passe à des questions si vous en avez.
Tiens je te laisse celui sans fil, je prends celui avec fil. Non, non, non, non, faut vraiment dans le micro parce que sinon, après, les gens qui vont essayer de suivre la version enregistrée, ne vont rien entendre.
Question : Est-ce qu’on peut espérer qu’avec IPv6, ce genre de problèmes pour les adresses publiques disparaîtront, c’est-à-dire est-ce qu’avec IPv6, on aura tous notre propre adresse publique, toutes les machines en fait ?
Benjamin Bayart : Ça c’est une vraie question compliquée. Disons qu’avec IPv6, il n’y aura plus de prétexte technique. Maintenant, le fait qu’il soit possible de faire propre, ça ne suffit pas pour que les opérateurs fassent propre. En particulier, la pénurie d’adresses sur Internet est quelque chose de relativement récent, les premiers accès Internet mobile datent d’il y a un petit moment, il n’y avait pas de raisons particulières. Même chose, cette mauvaise idée de distribuer des adresses IP privées, elle a été très en vogue par exemple chez AOL à la fin des années 90, pour des accès fixes. Ce qui créait des tas de problèmes puisqu’on voyait apparaître des centaines de milliers d’internautes derrière la même adresse publique qui était celle d’AOL, et donc on voyait apparaître une masse phénoménale de trafic à destination d’une seule adresse ; donc qui ne permettait plus aucun lissage dans le réseau ; qui créait un goulot d’étranglement, etc. Donc, ce n’est pas une idée nouvelle et les premières fois où c’est apparu, ce n’était pas à cause de la pénurie des adresses. C’était un choix politico-technique d’un opérateur. À l’heure actuelle, les opérateurs mobile ont décidé de distribuer des adresses IP privées, il n’y a pas de raison technique majeure à ça. C’est donc bien un choix politique. Et c’est un choix politique qui n’est pas neutre.
Décider de vendre un accès Internet amputé, en particulier, amputé de la faculté d’émettre c’est objectivement pas neutre.
Question : Moi j’avais une petite question, c’était vis-à-vis d’un des premiers slides que vous nous avez montrés sur la topologie d’Internet, c’était quelle est la différence si moi, par exemple, je m’inscris sur un FAI dit associatif comme ceux proposés par votre association, qu’est ce qu’il va se passer, vous n’êtes pas dépendants des FAI normaux ?
Benjamin Bayart : Alors, le fait d’avoir recours à un FAI associatif ou à un FAI normal, change structurellement très peu de choses. De toute façon, comme tout le monde, quand on vend de l’ADSL, on loue la ligne de cuivre à France Telecom parce que c’est France Telecom qui les possède toutes et l’Internet auquel on accède est le même. C’est le réseau public d’adresses gérées, dadada, qui est l’interconnexion des 40 000. La vraie différence qu’il peut y avoir, c’est, en fait, une question d’indépendance. À partir du moment où on sait ce que fait son FAI et où on a confiance en lui, tout va bien. Tant que j’ai confiance, dans Orange ou dans Neuf, pour savoir que je peux m’exprimer librement, tout va bien.
À l’heure actuelle, la majorité des FAI filtrent une partie du contenu. D’une manière qui n’est en général pas repérée par les non informaticiens. Mais par exemple, il est totalement impossible aujourd’hui, sur un accès Orange, d’héberger un serveur de mail. Pour quelle mauvaise raison ? Alors, on sait pour quelle mauvaise raison. C’est parce que, basiquement, un Windows qui est tout crevu de virus, ça passe son temps à bombarder la terre entière de spams, donc à se comporter comme un serveur mail, à émettre des mails et que le fait de filtrer ça, ça permet d’enlever 99% de la gêne publique générée par les virus des gens qui ont des ordinateurs mal installés et mal protégés. Sauf que, au prétexte de pallier l’ignorance de la majorité de la population, on interdit à une minorité de s’exprimer.
Ce qui crée un vrai problème politique. Ça, c’est typiquement le genre de problèmes qu’il n’y aura pas chez FDN. Ça, c’est pas demain la veille qu’on va filtrer quelque chose.
Question : Combien ça coûte, d’acheter des adresses publiques ?
Benjamin Bayart : Alors, je suis embêté. On m’aurait posé la question il y a 15 jours, j’aurais dit que ce n’était pas en vente. C’est-à-dire qu’une adresse, ça se demande poliment et si on a un bon argumentaire pour le demander, on l’obtient et elle ne coûte rien. Il se trouve que depuis quelques semaines, ce n’est plus gratuit, ce n’est plus non plus vraiment payant, puisque basiquement, il y a un tarif qui a été fixé par le RIPE, le Réseau IP Européen, qui est une association sans but lucratif basée à Amsterdam, dont le nom est en français, ce que je n’ai jamais bien compris, qui est chargée de distribuer les adresses IP pour toute l’Europe. Ils ont décidé qu’ils factureraient 50€ par morceau et par an. Alors, si tu demandes un paquet, un morceau, un bloc de 16 adresses IP, c’est 50€ pour les 16 adresses IP. Si tu demandes un bloc de 8 millions d’adresses IP, c’est 50€ les 8 millions d’adresses IP. C’est 50€, en fait, c’est simplement qu’ils ont besoin de se financer, qu’ils n’arrivent pas à trouver un modèle économique raisonnablement équitable, qui fasse porter la charge administrative aux gens qui génèrent du boulot administratif. Et donc, ils ont décidé qu’ils allaient faire 50€ par objet. Tu demandes un numéro d’AS, c’est 50€. Tu demandes un bloc d’adresses IP, c’est 50€, quelle que soit la taille du bloc, parce que c’est le même temps de travail pour lire le formulaire de demande, l’éplucher, vérifier qu’il est bon, que tu es un opérateur sérieux, que tu ne vas pas faire des bêtises, et puis enregistrer le tout dans la base de données. Mais ça n’a pas, il n’y a pas une bourse de l’adresse IP. Ça ne se vend pas, ça ne s’achète pas, ça ne se revend pas, bien évidemment. C’est-à-dire que quand on en n’a plus besoin, faut les rendre au RIPE. Ça ne se vend pas, ce n’est pas en vente libre. C’est un des rares bouts d’Internet dont on a réussi à ce qu’il ne soit pas en vente libre.
Question : Juste pour revenir sur Orange, vu que tu as expliqué le peering, j’ai entendu dire qu’ils avaient des problèmes avec YouTube récemment, apparement Orange filtre YouTube, alors je ne sais pas si tu as entendu parler de ça ?
Benjamin Bayart : Ben, j’en sais rien, moi je n’ai pas un accès chez Orange, donc je suis très embêté pour répondre. YouTube n’est pas filtré chez FDN, ça c’est certain, j’en aurais entendu parler. Il y a régulièrement des problèmes entre les gros opérateurs de réseau et les gros opérateurs de contenu, surtout en cette saison, en particulier parce qu’il y a un débat en cours, en Europe, suite à l’écriture du Paquet Telecom, sur les obligations de neutralité de l’opérateur vis-à-vis des contenus qu’il transporte. Et il y a des grosses batailles politiques en cours, sur le fait de savoir : est-ce que du NAT, c’est autorisé ? Changer les adresses - ce que j’ai expliqué, sur ce que fait la BiduleBox - est-ce que c’est neutre ? Est-ce que c’est pas neutre ? Est-ce que dire : « YouTube, il m’emmerde, ils vont passer par le câble complètement saturé là-bas comme ça le reste du réseau marchera bien », c’est neutre ? C’est pas neutre ? Est-ce que c’est simplement une agression commerciale ou est-ce que c’est une atteinte au réseau et donc un non respect des obligations de l’opérateur ? Voilà, il y a tout un tas de débats en ce moment là-dessus, pour savoir ce qui est acceptable, ce qui ne l’est pas. Et donc on risque de voir très régulièrement sortir des pointes comme ça, des décisions d’opérateurs qui sont juste destinées à prendre une position sur l’échiquier, mais qui ne sont pas forcément des décisions pérennes.
En particulier, si Orange fait exprès de pourrir l’accès à YouTube, ils vont s’en mordre les doigts mais d’une force pas croyable. YouTube n’en a juste rien à cogner des quelques millions d’abonnés d’Orange par rapport aux 2 milliards d’internautes et par contre, si YouTube ne marche plus chez Orange, j’ai un bon conseil : change de FAI.
Question : Et la fibre, dans tout ça ? (inaudible)
Benjamin Bayart : Et donc une fois qu’ils auront perdu leur … oui, enfin de la fibre, si t’as plus accès au contenu que tu veux regarder, ça sert juste à rien, prends un modem bas débit, tu verras, c’est bien aussi (rires). Mais, voilà, si Orange s’amuse à filtrer les gros opérateurs de contenus, ils n’auront plus d’abonnés. Donc, à l’heure actuelle, cette guerre est extrèmement déséquilibrée. Je pense que ça sert juste à marquer des prises de position de manière très ponctuelle ou que ce sont des accidents de parcours.
Question : Est-ce qu’au niveau de (inaudible) Cogent (inaudible) qu’on a pu voir ?
Benjamin Bayart : Ah ça, ça peut être autre chose. Si c’est des problèmes de peering lié à Cogent, en règle générale, quand il y a un problème réseau et qu’on parle de Cogent dans la phrase, c’est que quelqu’un chez Cogent a raté quelque chose. C’est une vieille habitude chez eux.
J’ai bien aimé, pendant un moment ça affichait du noir, ça faisait moins mal aux yeux.
Tiens regarde, on va faire ça, on va mettre un fond noir, ça fait beaucoup moins mal aux yeux. Et pour les gens qu’ont pas vu, voilà, les transparents quand moi, je travaille dessus, ils ressemblent à ça.
Voilà.
Question : Est-ce que tu pourrais revenir un petit peu sur les procédures d’obtention d’AS ? Comment ça se passe d’une manière simplifiée, par qui c’est contrôlé, est-ce qu’il peut y avoir des volontés politiques de les limiter ? Etc.
Benjamin Bayart : Alors, là dessus, alors comment ça se passe ? Si je décris ça de manière globale, l’autorité qui diffuse à la base, c’est l’ICANN dont le bras armé est l’IANA.
Donc, l’ICANN est une association de droit américain, dans laquelle le gouvernement américain est représenté mais pas de manière très centrale, c’est-à-dire qu’il a du poids mais moins que ce qu’on pourrait redouter. Trop à mon goût, mais moins que ce qu’on pourrait redouter.
L’IANA étant la branche qui est chargée de faire appliquer techniquement les décisions, les règles en fait, choisies par l’ICANN. L’IANA attribue de très gros blocs d’adresses IP, de plusieurs millions d’adresses, à cinq autorités régionales, une pour l’Amérique du Nord, une pour l’Amérique du Sud, une pour l’Europe, une pour l’Afrique, une pour l’Asie-Pacifique. Ces autorités régionales, ce qu’on appelle des RIR, des Regional Internet Registry, distribuent, elles, des blocs d’adresses et des numéros d’AS à des distributeurs locaux, qui basiquement sont à peu près n’importe qui, plutôt des opérateurs réseaux. Il y a un RIR en Europe, qui est le RIPE, et il doit y avoir quelques milliers de LIR, de Local Internet Registry, en Europe.
Donc, en fait, quelqu’un qui a besoin, pour un usage particulier ou professionnel d’un bloc d’adresses IP, doit s’adresser à un LIR, qui va sommairement regarder si sa demande est légitime ou si c’est juste complètement barge. Basiquement, si je demande 256 adresses IP pour mettre dans mon salon, a priori, on va m’envoyer chier. Par contre, si je viens avec 10 pages d’argumentaire sur pourquoi j’en ai besoin et pourquoi, pour développer telle application innovante, il me faut ces 250 adresses, c’est justifié du fait qu’il n’y a pas moyen de faire autrement, on me les accordera sans doute.
Donc, il y a des règles d’attribution qui sont basiquement que tant que t’as pas fini de te servir de celles qu’on t’avait donné la fois d’avant, t’es prié de pas en redemander ; que si tu en redemandes, tu dois faire la preuve du fait que tu ne les as pas gaspillées, en particulier si tu as donné des adresses IP publiques, alors qu’elles sont rares en IPv4, à ta machine à café et à ton imprimante, il y a des chances pour qu’on t’explique que non.
C’est déjà arrivé à plusieurs reprises que des gros opérateurs s’entendent répondre que non, parce qu’ils avaient gaspillé des milliers et des milliers d’adresses dans la façon de gérer leur réseau et qu’ils étaient priés d’apprendre à gérer leur réseau en gaspillant moins.
J’ai des souvenirs, il y a une dizaine d’années, de France Telecom qui avait eu des problèmes. Ils utilisaient à peu près 250 fois trop d’adresses dans la façon de router le réseau. Et donc, on leur a rapidement expliqué qu’il fallait arrêter de faire comme ça, il fallait qu’ils rangent un peu, plutôt que d’en demander des nouvelles.
Donc, la procédure elle est assez simple, tu contactes un LIR, t’expliques ce dont tu as besoin, tu remplis un assez long formulaire en anglais qui sera envoyé au RIPE, qui explique pourquoi t’en as besoin, pourquoi tu peux pas faire autrement, pourquoi une solution à base de traduction d’adresses en entrée ou en sortie, comme ce que j’ai expliqué tout à l’heure, ne suffit pas. En particulier, s’il y a des questions de chiffrement, s’il y a des questions de nombre de machines, des choses comme ça. Une fois que tu as tout bien expliqué, en général, on te les accorde.
Ça devrait changer dans un an et demi puisqu’il n’y en aura plus, et donc on aura du mal à les accorder, mais je ne sais pas ce que ça donnera dans un an et demi.
Question : Et à ce propos-là, est-ce qu’il est envisageable, est-ce que ça a déjà été envisagé par l’IANA de restructurer un petit peu l’attribution des plages… puisque quand on prend les entreprises pionnières de l’Internet, elles ont quand même des plages démentielles ?
Benjamin Bayart : Alors, si je reformule la question juste pour qu’elle soit enregistrée. Est-ce qu’on pourrait envisager de remettre en cause les attributions anciennes, en particulier celles des pionniers d’Internet qui ont des quantités ahurissantes d’adresses IP ?
Techniquement on pourrait. Ça a juste aucun intérêt. Vraiment aucun. C’est-à-dire que ça va coûter une véritable fortune, ça va foutre un bordel pas croyable dans le réseau, sachant que des adresses IP, une fois qu’on sera sorti du modèle v4 pour passer au modèle v6, il y en a une quantité telle qu’objectivement, on s’en fout.
On va distribuer des millions de milliards d’adresses IP à chaque abonné sur Internet et on pourra offrir un abonnement Internet au premier brin d’herbe venu. Et il en restera encore.
Faut repérer, je ne sais pas si vous êtes tous familiers de notions mathématiques, il y a 2 puissance 32 adresses IP à l’heure actuelle, ça, ça fait 4 milliards. Il y a 2 puissance 128 adresses IPv6. Je ne sais pas si ça parle à tout le monde, mais ça veut dire qu’on est en milliards de milliards de milliards de milliards et qu’il y en aurait plusieurs tendance beaucoup de cette quantité là. D’accord ?
Donc on est sur des ordres de grandeur qui sont assez compliqués à manipuler, ne serait-ce qu’intellectuellement.
En supposant qu’à chacune des 4 milliards d’adresses IPv4, on donne un bloc qui représente le même pourcentage d’adresses IPv6, le bloc est plusieurs milliards de fois plus grand que la totalité de l’espace d’adressage d’IPv4. D’accord ?
En supposant qu’on donne plusieurs millions de milliards d’adresses IP à chacun qui se connecte à Internet en v6, on peut connecter à peu près 2 puissance 64 individus sur la planète. C’est-à-dire 16 milliards de milliards de personnes. Non seulement on peut connecter n’importe quel être humain en vie, présent passé ou avenir, mais on peut objectivement adresser le plus petit caillou, sans difficulté majeure.
Donc, dépenser une véritable fortune à restructurer le réseau en allant reprendre des adresses anciennes, ça coûte à peu près le même prix que la bascule de v4 à v6. Donc, c’est pas spécialement intéressant.
Et si cette bascule n’a pas encore eu lieu alors que la pénurie est prévue depuis 10 ans - les courbes qui annoncent la pénurie et la date de fin, ça fait 10 ans que tout le monde les connaît, et ça fait 10 ans que IPv6 est prêt - si la bascule n’a toujours pas eu lieu, c’est qu’il n’y avait pas d’enjeu. Il n’y avait pas d’urgence, c’était pas pressé. Et chacun sait qu’en matière d’économie, un problème qui est prévu pour demain est un problème qui peut attendre encore au moins deux jours. Donc je pense que les bascules vers IPv6 vont se faire vite et fort à partir du moment où les gros opérateurs n’auront plus d’adresses. Et donc, je m’attends en France à ce qu’on bascule massivement sur IPv6 quand Orange, Free, Neuf et Numéricable n’arriveront plus à obtenir d’adresses.
Organisateur : On va prendre une ou deux questions max parce qu’il faut qu’on parte.
Benjamin Bayart : Il y en a une devant.
Organisateur : Là, je l’ai vu tout à l’heure.
Question : Bonjour,
Benjamin Bayart : Faut parler plus fort et dans le micro !
Question : Vous avez parlé tout à l’heure d’une tarification des transferts de données vis à vis de différents opérateurs. Est-ce qu’on pourrait avoir un ordre d’idée du prix du giga pour ainsi dire ? Pour savoir combien coûte un abonné à son opérateur, s’il est extrêmement complexe ?
Benjamin Bayart : Mon problème, c’est que l’ordre de grandeur de prix est dans des unités qui sont complexes à lire pour quelqu’un qui n’est pas technicien. L’ordre de grandeur c’est à peu près 4 à 5$ le megabit par seconde, en facturation mensuelle au 95ème percentile sur du transit international.
Donc voilà, jusque-là, illisible. Il y a un autre moyen de regarder ça. C’est, il ne faut pas regarder un abonné car quand on regarde un abonné, on a un biais statistique. Faut regarder combien coûte l’ensemble des abonnés. Et en fait ce qu’il faut, c’est regarder dans la structure de coût d’un opérateur, quelle est la partie indépendante du trafic réel, et quelle est la partie linéairement dépendante ou pas linéairement dépendante mais dépendante de la quantité de trafic réel. Et basiquement, dans les structures de coût des gros opérateurs, il y a moins de 5% qui est lié à la quantité de bande passante consommée.
C’est-à-dire que si tu vas voir le patron de Free et que tu lui proposes deux choix économiques, l’un qui est de diviser par deux la consommation de bande passante de ses abonnés, l’autre qui est de diviser par deux le prix de la location de la ligne chez France Telecom, je peux te dire qu’il ne va pas réfléchir une demi-seconde. D’accord ? Il y en un des deux qui lui permet d’économiser à peu près 4% de son chiffre d’affaire, l’autre qui lui permet de diviser à peu près par deux sa structure de coût. C’est très vite vu. Donc la bande passante réellement consommée sur le réseau a un coût réel, mais en matière d’accès fixe, plutôt marginal.
On est sur un mode de fonctionnement très différent dans le mobile. (Non le blanc ça fait vachement mal aux yeux en fait) (rires).
Donc, la bande passante sur le fixe coûte très peu. En fait, parce que le lien le plus coûteux, c’est le lien entre toi et le premier nœud de raccordement. Or sur le fixe, sur ton accès ADSL, on t’a vendu 20 meg, que tu t’en serves ou pas, il ne peut pas servir à autre chose.
Par contre, dans le mobile, tu es sur une zone d’accès radio partagée et quand tu commences à saturer une zone d’accès radio partagée, il faut doubler l’infrastructure ; ce qui n’est pas le cas dans le fixe.
Dans le fixe, les 20 megabits que tu as sur ta ligne ADSL, ils te sont 100% dédiés entre toi et le central téléphonique.
Dans le monde du mobile, quand il faut doubler la capacité du réseau, il faut faire x2 son investissement. Dans le monde du fixe, quand il faut doubler la capacité du réseau, il faut en gros rajouter 10% dans l’investissement. Donc ce n’est pas du tout, du tout, du même ordre de grandeur.
Question : Toujours en parlant de IPv6, si chaque élément a une IP publique, ça veut dire qu’il n’y a plus besoin de traduction d’IP…
Benjamin Bayart : Oui,
Question : …d’adresses IP, et donc est-ce que ça veut dire que le spoofing n’est plus possible ?
Benjamin Bayart : Ah ben si, le spoofing est toujours possible. Le spoofing, c’est vachement simple.
C’est, moi quand j’écris à ma maman, que je suis à la plage, je mets son adresse sur le devant de l’enveloppe, puis derrière l’enveloppe, je mets Nicolas Sarkozy, virgule, Palais de l’Elysée, virgule, Paris. J’ai spoofé son adresse. Ça fait de moi un très dangereux hacker de l’Internet.
Le spoofing est toujours possible. Après, ce qui serait magique, c’est que je reçoive par un moyen ou par un autre, le courrier destiné au Palais de l’Elysée. C’est beaucoup plus rigolo comme variété de spoofing, d’accord.
Mais le spoofing qui est juste usurper une adresse IP en émission, il n’y a rien de plus simple, c’est l’enfance de l’art, en matière de hacking sur du réseau.
Question : Je parle bien en réception, oui.
Benjamin Bayart : Ah ben, en réception, ça suppose toujours une interception et c’est évidemment toujours possible. Une écoute judiciaire, c’est du spoofing de ligne téléphonique. Basiquement, Monsieur Lapolice, il reçoit tes appels en même temps que toi. Et tu ne peux pas l’empêcher. Donc non, la seule chose qui puisse empêcher le spoofing, c’est la signature. Pour le coup, c’est des questions comme le chiffrement. À partir du moment où il y a chiffrement et donc identification forte de l’émetteur, je suis certain que le message a été signé par telle personne, et il est certain que seul moi peut le lire.
Donc, on est vraiment sur un modèle totalement en dehors du réseau en fait. La couche de réseau ne comprend rien à ce qu’elle transporte et donc elle peut se faire spoofer, on peut se faire usurper une adresse.
Par contre, à l’heure actuelle, les mécanismes de chiffrement n’ayant pas encore été cassés par les mathématiciens, un simple chiffrement RSA à clé symétrique, qui est d’une banalité affligeante dans la vie de tous les jours, c’est-à-dire que c’est celui qu’il y a entre un site Web et toi quand t’es en HTTPS, ça donne des garanties de protection qui sont à peu près similaires à ce qu’on utilise dans les messageries entre le Quai d’Orsay et les ambassades. Donc on est quand même sur du assez haut de gamme.
Donc, je ne sais plus quand est le tome 2. Lundi soir, je crois.
Organisateur : Donc voilà, effectivement, le tome 2, c’est lundi prochain, donc en amphithéatre « Jean Moulin ». L’amphithéâtre Jean Moulin n’est pas au 27, donc là où vous êtes ce soir, mais au 13 rue de l’Université, donc, c’est à deux pas d’ici. On mettra des plans sur le site www.libertesnumeriques.net pour que vous puissiez repérer. Et enfin, la troisième partie, le 4 mai, donc le mercredi 4 mai, toujours à la même heure, 19h15, mais cette fois en amphithéâtre Albert Caquot, les plans seront également disponibles sur Internet. Merci beaucoup d’avoir été présent ce soir et donc à lundi prochain.